


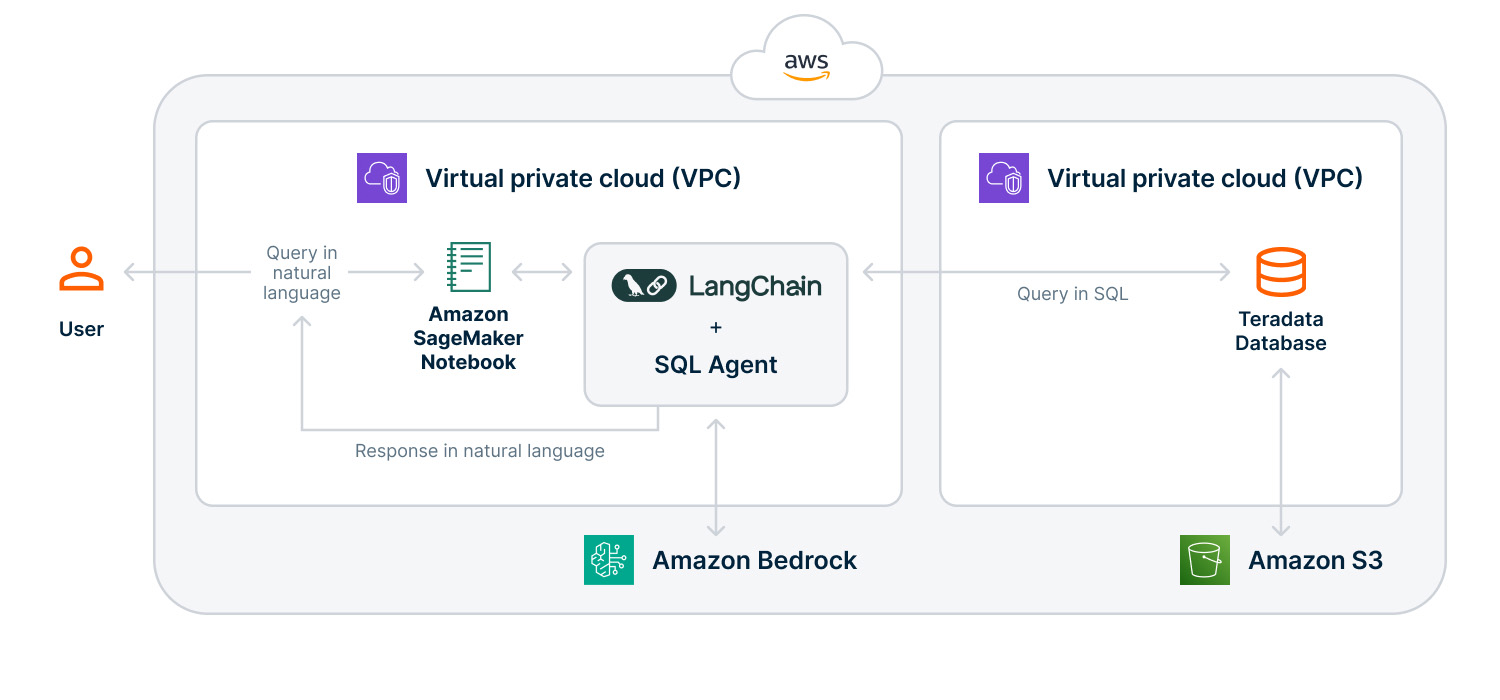
In 2023, we witnessed many examples of building text-to-SQL generative AI prototypes, showcasing the potential for business teams to interact with their databases using natural language. However, scaling these generative AI applications for large lakehouse and warehouse environments presents privacy and security challenges, operational inefficiencies, and financial constraints. Today, we can use Amazon Bedrock’s fully managed AWS service that offers a choice of high performing foundation models (FMs), LangChain’s flexible open-source framework, and Teradata Vantage™ analytic warehouse or lakehouse environments to effectively mitigate these challenges.
Let’s take a closer look at each of these considerations:
- Security and privacy challenges. Large Language Models (LLMs) require specific datasets, knowledge bases, or catalogs to generate optimal SQL queries. This can be problematic when dealing with highly sensitive data that can’t be shared with model providers, potentially discouraging further development.
- Solution: Amazon Bedrock also offers a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI principles. Amazon Bedrock helps ensure that all proprietary data fed to the LLM stays under your control. Your data is not shared with model providers and will not be used to improve base models. This provides a secure way for developing generative AI applications without compromising sensitive data. For this example, we’ll build our generative AI text-to-Teradata SQL with Anthropic Claude-3 offered via Amazon Bedrock.
- Operational inefficiencies: The deployment of generative AI apps requires considerable experimentation with a variety of LLMs to identify the most suitable model and configuration. This process can be time-consuming, complex, and costly.
- Solution: LangChain provides an easy-to-use open-source framework with multiple SQL chains, SQL agents, and tools optimized for querying SQL databases, which accelerates the development process. When coupled with Amazon Bedrock's single API, which interfaces with a variety of chat models, LangChain accelerates the creation of POCs and the deployment of generative AI applications. These two tools together reduce the complexity and time involved in model selection and integration. With Amazon Bedrock, we can experiment with models from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon via one interface.
In addition to these two tools, Vantage facilitates the analysis of data stored externally in object storage. We can leverage the Teradataml library and its native object storage to read data inside Amazon S3, Google Cloud, and Azure Blob. This minimizes costly data transfer and allows developers to work within Vantage using foreign tables without needing to transfer data into Vantage or use additional storage in their Vantage environment. - Financial constraints: LLMs can generate inefficient queries that could result in high compute costs.
- Solution: To mitigate these financial risks, we recommend setting thresholds and alerts on your service providers. For example, Teradata VantageCloud Lake on AWS offers financial governance features that make it easy to set automated alerts based on consumption thresholds. Another solution that we’ll explore in the next article is decoupling the generation of the query from the execution, giving you the opportunity to review the query and ensure it's optimized before it’s executed against the Vantage database.
Let’s get started!
This tutorial demonstrates how to build a LangChain implementation of an agent to generate and execute advanced SQL queries compatible with any LLM available on Amazon Bedrock. This agent will connect to a Vantage environment to analyze data stored in Vantage and object storage, including Amazon S3, Google Cloud, and Azure Blob. Users can ask business questions in natural English and receive answers with data drawn from the relevant databases.
View the complete application in a static version of a Jupyter notebook here.
For proofs-of-concept (POCs) and testing, we recommend using a dedicated testing environment to avoid impacting production systems. You can access a free Vantage environment at ClearScape Analytics™ Experience. Watch a walkthrough demonstration of the ClearScape Analytics Experience interface here.
While Amazon Bedrock and LangChain address many operational challenges, LLMs may still accidentally delete files by mistake, or a user may request commands to DELETE or DROP a table. To mitigate these risks, we recommend that you provide the user with read-only access to the Vantage analytic databases to prevent any destructive statements.
1. Install dependencies
We develop our application in a Amazon SageMaker Studio JupyterLab environment, as it allows for seamless integration with Amazon Bedrock APIs. For help setting up a Jupyter Lab environment on Amazon SageMaker, watch this video. This application can also be run on your preferred IDE; you will need to pass in AWS credentials as parameters when initiating the boto3 client.
Let’s begin by installing the necessary packages for this notebook. We use the AWS SDK for Python boto3 to interact with AWS services directly and facilitate connection to the Amazon Bedrock API, the LangChain libraries, and teradataml.
The teradataml package provides a pandas-like experience for data analytics. It creates a teradataml virtual DataFrame that serves as a reference to database objects, allowing operations directly on Vantage without transferring entire datasets to the client, except when needed.
#Install dependencies
%pip install --upgrade --quiet boto3
%pip install --upgrade --quiet langchain langchain_community langchain_aws
%pip install --upgrade --quiet teradataml
2. Import libraries and set up environment
Next, we import our libraries and set up our environment. We import LangChain’s SQLDatabase class: a wrapper around the SQLAlchemy engine to facilitate interactions with databases using SQLAlchemy’s Python SQL toolkit and ORM capabilities.
We use the create_sql_agent function to build a SQL agent given a language model and the database. This SQL agent will use the designated LLM to generate and execute SQL queries and as a reasoning tool to decide which actions to perform.
And finally, we import LangChain’s ChatBedrock class that serves as a common interface for using Bedrock's LLMs on AWS that support chat functionalities.
import os
import getpass
import warnings
import boto3
from langchain_community.utilities import SQLDatabase
from langchain_community.agent_toolkits import create_sql_agent
from langchain_aws import ChatBedrock
warnings.filterwarnings("ignore")
3. Connect to a Vantage database.
To establish a secure and efficient connection to any Vantage edition, we use LangChain’s SQLDatabase.from_uri method to create an engine from the database URI.
If you’re using ClearScape Analytics Experience to provision a free Teradata environment, you’ll need the password and host URI for the environment found in the connection details portion of the dashboard.
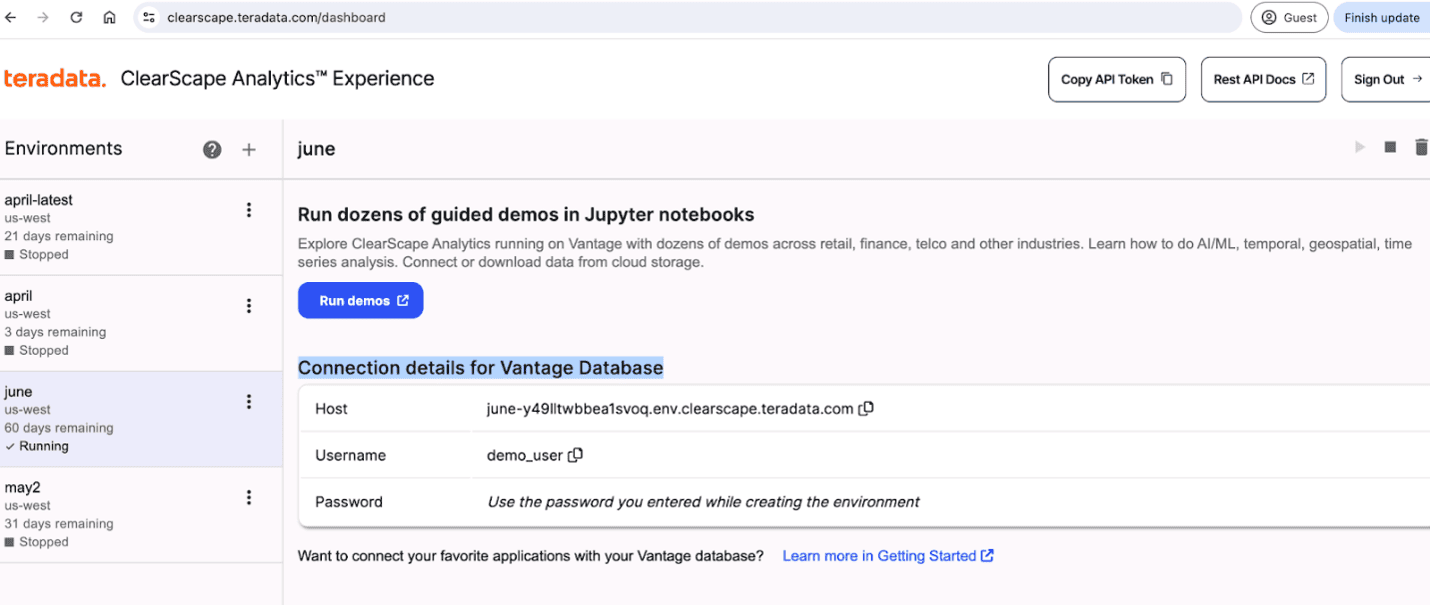
ClearScape Analytics Experience dashboard
user = input("Enter your username: ")
password = input("Enter your database password: ")
host_uri = input("Enter your database host URI: ")
database = input("Enter the name of a database you want to connect to: ")
# Set up Teradata connection
connection_uri = f"teradatasql://{user}:{password}@{host_uri}/{database}"
db = SQLDatabase.from_uri(connection_uri)
print(db.dialect)
Ensure that you replace the demo_user, password, and host_uri with the appropriate values.
Also note that teradatasqlalchemy was automatically installed with teradataml, which enables SQLAlchemy to detect the teradatasql dialect when we invoke db.dialect.
4. Load data for the demo to Vantage
When working with Vantage for data analysis, you have two options:
-
Analyze data stored externally in object storage. This method uses native object storage integration to create foreign tables inside the database. Point this virtual table to an external object storage location like Google Cloud, Azure Blob, or Amazon S3 and then use SQL to analyze the data. This minimizes data transfer and allows you to work within Vantage using foreign tables without needing additional storage in your Vantage environment.
-
Download data into your local Vantage environment. Alternatively, you can use native object storage integration to ingest data at scale into Vantage using one SQL request. Downloading data can result in faster execution of some steps that perform the initial access to the source data.
Let’s explore the data where it resides in Amazon S3 by creating a foreign table with Native Object Store (NOS) and pointing to the Amazon S3 object URL. This example uses a public S3 bucket. To set up access to a private bucket with an Authorization object, review the NOS documentation here.
load_data = """ CREATE FOREIGN TABLE demo_user.retail_marketing
USING (
location('/s3/dev-rel-demos.s3.amazonaws.com/bedrock-demo/Retail_Marketing.csv')
); """
db.run(load_data)
Refresh your connection and confirm that your data has loaded properly. When you call the following methods, you’ll see the database dialect as teradatasql, an array of usable table names, and a dictionary with detailed context information about the retail_marketing table, including its schema and sample data:
db = SQLDatabase.from_uri(connection_uri)
print(db.dialect)
print(db.get_usable_table_names())
print(db.get_context())
As you can see, native object storage integration with Vantage helps minimize data transfer, reducing operational and financial costs. You don’t have to pay for additional storage of the data you’re analyzing, as it remains in S3.
5. Set up the Amazon Bedrock client
First ensure you have requested and been granted access to the foundation model you want to use. In this example, we are using Anthropic Claude 3 Sonnet.
Next, initialize the bedrock-runtime client and define the LLM using the ChatBedrock interface. When defining the ChatBedrock, set the Amazon Bedrock base model id, the client as boto3, and the common inference parameters.
We use the optional parameters temperature to make our Teradata SQL outputs more predictable.
- Temperature: Setting it to 0.1 ensures the model favors higher-probability (more predictable) words, resulting in more consistent and less varied outputs.
For a complete list of optional parameters for base models provided by Amazon Bedrock, visit the AWS docs.
# Set up the Bedrock client
boto3_bedrock = boto3.client('bedrock-runtime')
## If using an external IDE or Jupyter notebook hosted externally pass in credentials
# boto3_bedrock = boto3.client(
# service_name="bedrock-runtime",
# region_name="us-west-2",
# aws_access_key_id=getpass.getpass(prompt='Enter your AWS Access Key ID: '),
# aws_secret_access_key=getpass.getpass(prompt='Enter your AWS Secret Access Key: '),
# aws_session_token=getpass.getpass(prompt='Enter your AWS Session Token: ')
# )
# Define the LLM
llm = ChatBedrock(
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
client=boto3_bedrock,
model_kwargs={
"temperature": 0.1,
}
)
6. Create the SQL agent
With the connection to Vantage established and our database (db) and LLM defined, we’re ready to create using the create_sql_agent() function.
We pass in our llm and db as required parameters and set agent_type to "zero-shot-react-description" to instruct the agent to perform a reasoning step before acting.
We set verbose to True so that the agent can output detailed information of the intermediate steps. Additionally, we set handle_parsing_errors to True, ensuring that errors are sent back to the LLM as observations for the LLM to attempt to address.
agent=create_sql_agent(
llm=llm,
db=db,
agent_type="zero-shot-react-description",
verbose=True,
handle_parsing_errors=True
)
7. Set optional observability with LangSmith
To enhance observability in our application, we can configure environment variables for LangSmith. It comes pre-installed with the LangChain library, so all you need to do is generate a LangSmith API key here and set up the following environment variables to start monitoring your applications. Uncomment the LangSmith variables if you want to use the LangSmith tracing functionalities to log and view executions of your LLM application.
##If you are using tracing via LangSmith, set these variables:
##os.environ["LANGSMITH_API_KEY"] = getpass.getpass()
##os.environ["LANGSMITH_TRACING_V2"] = "true"
8. Invoke the SQL agent
Invoke the agent with an exploratory command or question and observe each step. For example, you can ask it to describe the retail marketing table.
# Run the agent to describe a table
response = agent.invoke("Describe the retail marketing table")
As soon as we invoke the agent, it begins performing a sequence of thought and action. Notice how this behavior is very similar to how a data scientist would approach interacting with a database.
Data scientists and data analysts usually start with a trial query to understand the table schema and look at initial rows. This exploration helps in constructing queries. If errors happen, they edit their queries until they’re successful. Similarly, LangChain agents ensure LLMs are firmly rooted in real data by describing the database, including its table structure, data samples of the top few columns, and sample SELECT queries. This reduces hallucinations and ensures more reliable and accurate SQL query generation.
If we inspect our application using LangSmith, we can see all inputs and outputs in every step of the chain. You can view a public run of this example question here. Note that the first call to Anthropic Claude 3 is the third step in our chain. In this third step, the input includes additional prompt engineering that instructs our LLM to utilize supplementary tools such as sql_db_query, sql_db_list_tables, sql_db_query_checker, and sql_db_query, along with a specified format for thought and action sequences. This SQLDatabase agent has been engineered with prompts to emulate the approach taken by data scientists when exploring and analyzing data. 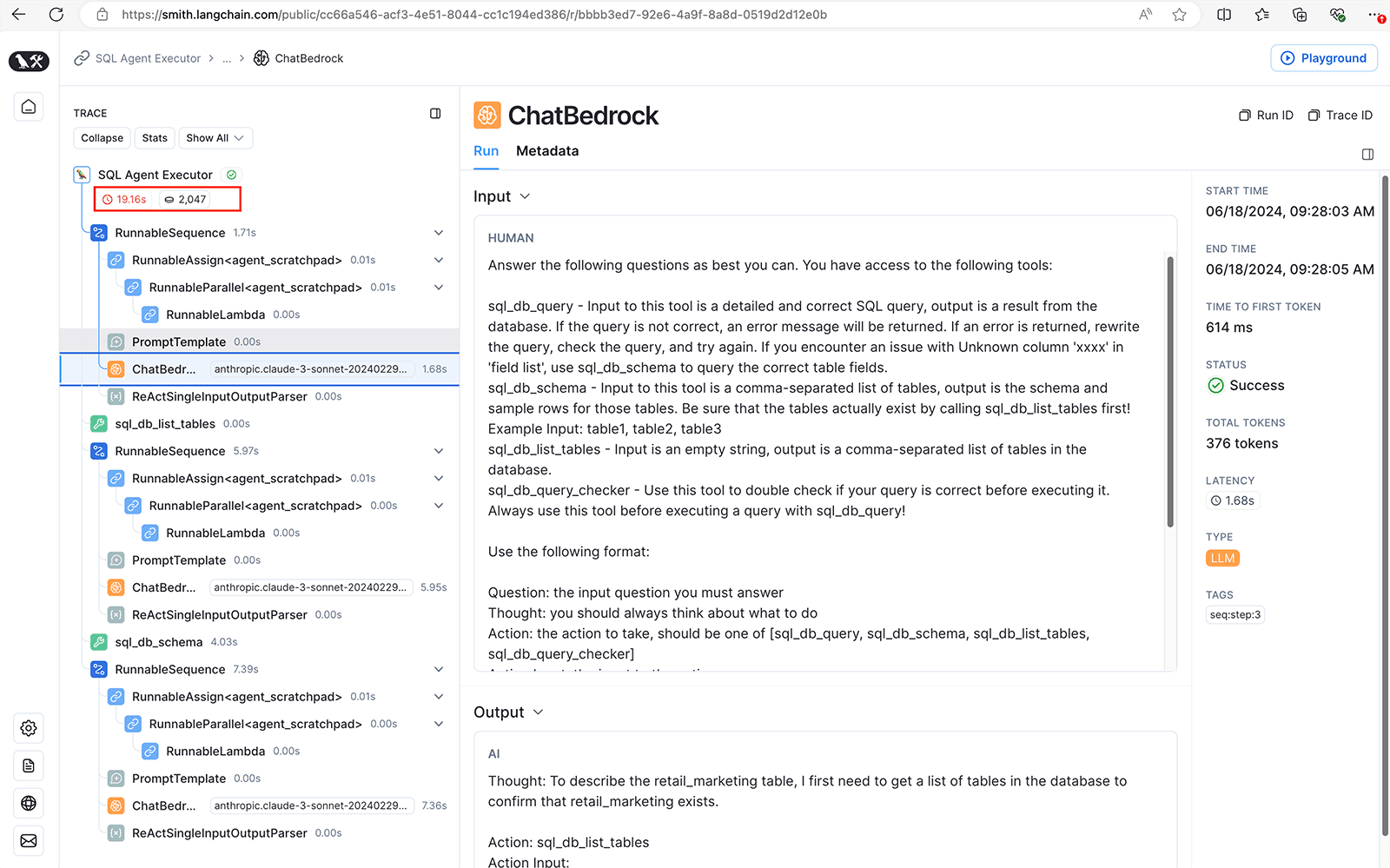
LangSmith interface displaying trace of SQL agent
The agent’s first thought is to check the list of tables in the database using the sql_db_list_tables tool, which employs the db.get_usable_table_names() method to retrieve table names.
Next, it uses sql_db_query to fetch detailed information about the retail_marketing table’s schema, including column names, data types, and sample rows, by calling db.get_table_info_no_throw().
This approach follows best practices from Rajkumar et al., 2022 (https://arxiv.org/abs/2204.00498), which found that providing detailed schema information enhances text-to-SQL performance.
9. Optimize the query with prompt engineering
The agent can answer various questions about our data using only table names, schemas, sample rows, and the LLM’s knowledge of Teradata SQL. Although it can recover from mistakes, there's significant room for improvement. For example, execute the following query:
response = agent.invoke("What is the month with the highest number of marketing engagements?")
We get the correct answer, but upon inspecting the execution of each step, we see that the agent initially produced incorrect SQL. Executing that SQL resulted in the following error:
Error: (teradatasql.OperationalError) [Version 20.0.0.12] [Session 1185] [Teradata Database] [Error 3706] Syntax error: expected something between the 'DESC' keyword and the 'LIMIT'
The LLM was able to read and recover from the error, but this mistake was costly. It resulted in our agent using 23,913 tokens and taking 49.56 seconds to provide the correct answer. You can view a public view of this execution via this LangSmith trace. We can optimize this with additional prompt engineering, reducing the tokens to under 6K tokens and execution time under 20 seconds! 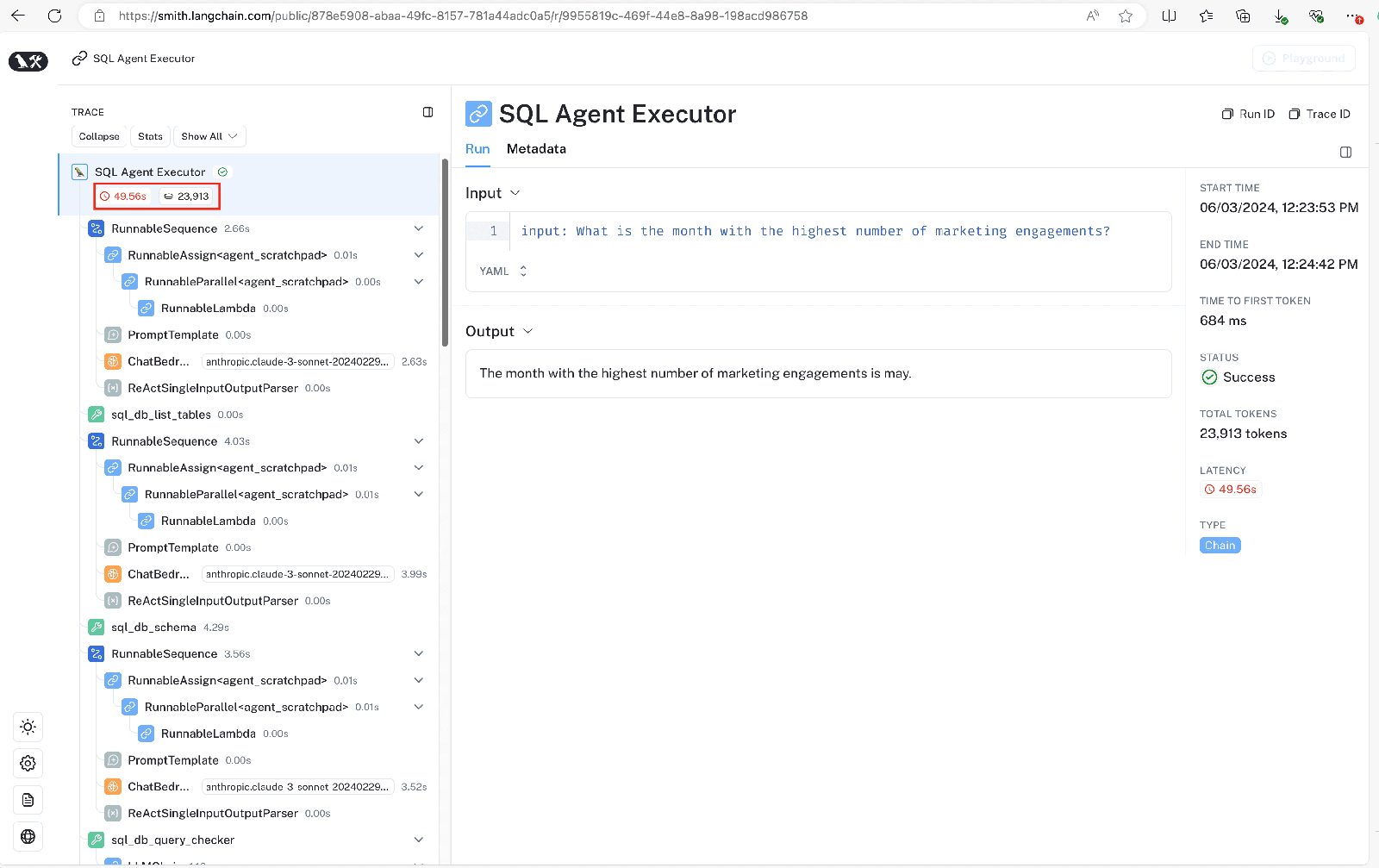
Let’s optimize our prompt to reduce the iterations needed for the LLM to generate and translate text to SQL. We import a ChatPromptTemplate class from langchain_core.prompts to build flexible reusable prompts in our agent. Then we define the following:
- A prefix, detailing specific rules and guidelines for Teradata SQL
- Format instructions, outlining a structured sequence (Question, Thought, Action, Action Input, Observation)
- A suffix, preparing the agent to begin processing by setting placeholders for the input question and initial thoughts
from langchain_core.prompts import ChatPromptTemplate
prefix = """You are an helpful and expert TeradataSQL database admin. TeradataSQL shares many similarities to SQL, with a few key differences.
Given an input question, first create a syntactically correct TeradataSQL query to run, then look at the results of the query and return the answer.
IMPORTANT: Unless the user specifies an exact number of rows they wish to obtain, you must always limit your query to at most {top_k} results by using "SELECT TOP {top_k}".
The following keywords do not exist in TeradataSQL:
1. LIMIT
2. FETCH
3. FIRST
Instead of LIMIT or FETCH, use the TOP keyword. The TOP keyword should immediately follow a "SELECT" statement.
For example, to select the top 3 results, use "SELECT TOP 3 FROM <table_name>"
Enclose all value identifiers in quotes to prevent errors from restricted keywords. Append an underscore to all alias keywords (e.g., AS count_).
Always use double quotation marks (" ") for column names in SQL queries to avoid syntax errors.
NOT make any DML statements (INSERT, UPDATE, DELETE, DROP, etc.) to the database.
If the question does not seem related to the database, just return "I don't know" as the answer
You have access to the following tools:"""
format_instructions = """You must always the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
(this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Don't forget to prefix your final answer with the string, "Final Answer:"!"""
suffix = """Begin!
Question: {input}
Thought:{agent_scratchpad}"""
We then combine our prefix, {tools}, which is populated dynamically, format_instructions, and suffix to create a custom_prompt template.
custom_prompt = ChatPromptTemplate.from_template("\n\n".join([
prefix,
"{tools}",
format_instructions,
suffix,
]))
We initialize and invoke our agent using the create_sql_agent function, but this time we also pass in our custom_prompt.
agent=create_sql_agent(
llm=llm,
db=db,
agent_type="zero-shot-react-description",
verbose=True,
handle_parsing_errors=True,
prompt=custom_prompt
)
response = agent.invoke("What is the month with the highest number of marketing engagements?")
This time our response was returned within 19.30 seconds and required 5,692 tokens! Inspect this public run on LangSmith. This time the LLM did not generate the query using the restricted LIMIT keyword. This additional prompting enables it to produce the final answer with fewer iterations.
Final answer: The month with the highest number of marketing engagements is May.

10. You can try your own question
Here are some sample questions that you can try out:
- What is the average income for Phoenix?
- Which city has the highest average income?
- What is the average age of married people?
- Which profession has the most married people in Phoenix?
- What is the month with the lowest sales?
- What is the month with the highest number of marketing engagements?
- What is the payment method distribution?
- What is the average number of days between a customer's last contact and their next purchase?
- What is the relationship between marital status and purchase frequency?
- What is the most effective communication method for reaching customers who have not purchased from our company in the past 6 months?
try:
question = input("\nEnter your natural language query: ")
response = agent.invoke(question)
print(f"Query: {question}\nResponse: {response}")
except Exception as e:
print(f"An error occurred: {e}")
Conclusion
We’ve explored the development of fully autonomous text-to-Teradata SQL agents using LangChain and Amazon Bedrock while addressing critical considerations around security, operational efficiency, and financial governance. We’ve highlighted solutions to mitigate these risks, including:
- Leveraging compliant LLMs from trusted providers like AWS to safeguard sensitive data
- Utilizing platforms such as Amazon Bedrock and frameworks like LangChain to accelerate development
- Implementing consumption thresholds and alerts on service providers to manage costs effectively
In the next article, we’ll explain how you can combine the components running behind these agents using LangChain Expression Language (LCEL) for greater control over these fully automated systems. We’ll build agents from scratch and separate the SQL generation from execution, which not only gives us better control over risks but also enables us to build more custom and flexible text-to-SQL agents.
Meet the authors
Janeth Graziani is a Developer Advocate at Teradata who enjoys leveraging her expertise in technical writing to help developers navigate and incorporate new tools into their tech stacks. When Janeth isn’t exploring a new tool for her stack or writing about it, she’s enjoying the San Diego weather and beaches with her family. Connect with Janeth on LinkedIn.
Doug Mbaya is a Senior Partner Solution architect with a focus in AI/ML and analytics. Doug works closely with AWS partners, helping them integrate data and analytics solutions in the cloud. He’s passionate about machine learning (ML) and helping customers translate their ML needs into solutions using AWS AI/ML services. Connect with Doug on LinkedIn.
Megha Kumsi is a Sr. Technical Account Manager at AWS. She provides strategic technical guidance to help independent software vendors (ISVs) plan and build solutions using AWS best practices. In her free time, she likes gardening and travelling with her family. Connect with Megha on LinkedIn.