
What if our business teams could talk to structured query language (SQL) databases in plain English language? Large language models (LLMs) are making this possible. You can leverage the same LLMs used by ChatGPT, Claude, and soon, Bard, to build your own generative artificial intelligence (AI) applications that query your database tables. To do this effectively, you need to have a good grasp of the new field of prompt engineering. Prompt engineering is not as simple as asking ChatGPT to help craft an email. It involves providing context to the LLM and carefully orchestrating the model interactions with your own application. In this hands-on guide, you’ll learn foundational elements and techniques of prompt engineering to programmatically interact with LLMs in the most effective way. As a developer, these skills will allow you to return an output most suitable for your generative AI applications, preventing inconclusive or inaccurate model outputs.
This is the first article in a series offering a free, interactive online environment for coding, detailed step-by-step instructions for building your generative AI engine, and customizable templates to help you get started. You’ll learn to leverage LangChain‘s open-source framework to build reusable prompt templates and interact with any LLM of your choice. In the second article, we’ll apply our learnings and additional advanced techniques in prompt engineering to query Teradata VantageCloud databases using conversational English.

Image by Author created using ChatGPT
What is prompt engineering?
Under the hood, LLMs are sophisticated prediction engines that rely on mathematical computations and extensive data to effectively respond to user queries with coherent outputs. An end user will feed these LLMs a string as an input—for example, “Why is the sky blue?” This is also known as the prompt. The model then generates a continuation of words, predicting subsequent words based on the statistical likelihood, internal parameters, and any techniques or constraints set by the developer.
Prompt engineering has become a critical process in this context. Prompt engineering is the process of influencing the model's continuous responses by meticulous crafting of prompts. These prompts can incorporate elements such as instructions, context, input, output instructions, and techniques like few-shot prompting and retrieval augmented generation (RAG). Few-shot prompting involves providing the LLM with a few example queries and the expected output to guide its responses. RAG allows the LLM to access external database information and then generate an answer based on the knowledge and prompt instructions. Both techniques enhance the LLM’s ability to generate accurate and context-aware responses.
While prompt engineering is an accessible and strategic approach to guide LLM’s it is different from the process of fine-tuning. Fine-tuning involves preparing pretrained models by preprocessing new training datasets, as well as adjusting weights and internal parameters based on new data. The fine-tuning process often requires advanced technical expertise and significant computational power. In contrast, prompt engineering is a more user-friendly method for manipulating LLM’s outputs and leverages the capabilities of LLMs through prompt design. In this tutorial, we’ll apply five elements of prompt engineering:
- Instruction. Guides the LLM on what task it should perform.
- Context. Gives the LLM additional information to help it understand the environment and constraints within which it should operate.
- Input. The query to which we want a response.
- Output instruction. The format in which we want the response returned.
- Few-shot prompting/in-context learning. Examples we can provide the LLM to influence better performance.
There are more advanced techniques beyond these, which can help us achieve better results on different tasks.
Applying prompt engineering with LangChain
We'll be developing in a Jupyter Notebook environment within ClearScape Analytics™ Experience, our free hands-on demo environment. We’ll also leverage LangChain’s framework to help us interact with LLMs.
LangChain introduces a framework that facilitates the integration of LLMs with other tools and sources to build more sophisticated AI applications. LangChain does not serve its own LLMs; instead, it provides a standard way of communicating with a variety of LLMs, including those from OpenAI and Hugging Face. LangChain accelerates the development of AI applications with building blocks. We’ll learn to leverage the following building blocks:
- llms. LangChain's llms class is designed to provide a standard interface for all LLMs it supports, including OpenAI, Hugging Face, and Cohere.
- PromptTemplate. LangChain’s PromptTemplate class is a predefined structure for generating prompts for LLMs. They can house our elements of prompt engineering: instructions, context, input, output, and few-shot examples, making prompt templates versatile and reusable across LLMs.
- Chains. When we build complex AI applications, we may need to combine multiple calls to LLMs and to other components. LangChain’s expression language (LCEL) allows us to link calls to LLMs and components. The most common type of chaining in any LLM application combines a prompt template with an LLM and, optionally, an output parser.
Creating an environment
Create your free ClearScape Analytics Experience account or sign in. Here, we can run our code in a Jupyter notebook environment and access data for our upcoming piece. This site enables us to configure free, fully functional, lightweight cloud environments, featuring ClearScape Analytics on Teradata VantageCloud. Within these environments, we can create and alter databases with limited data loads. The same capabilities are available on all Teradata’s platforms, supporting large-scale data processing with hundreds of nodes and petabytes of data.
ClearScape Analytics Experience landing page
Once you’ve signed in, select the Create button to provision a new environment.
1. Enter the name of your environment.
a. Note: Environment name must start with a lowercase letter.
Creating a ClearScape Analytics Experience environment
2. Type a unique password.
a. Note: Save your password, as you will not be able to retrieve it later.
3. Select your region and select Create to initialize the environment.
New ClearScape Analytics Experience environment
Running the environment using Jupyter
Select the Run demos using Jupyter button to open the Demo.index tab. At the top of the left pane, select the blue + button to open the Launcher tab and select Python 3 (ipykernel) Notebook.
Launcher in ClearScape Analytics Experience Jupyter notebook
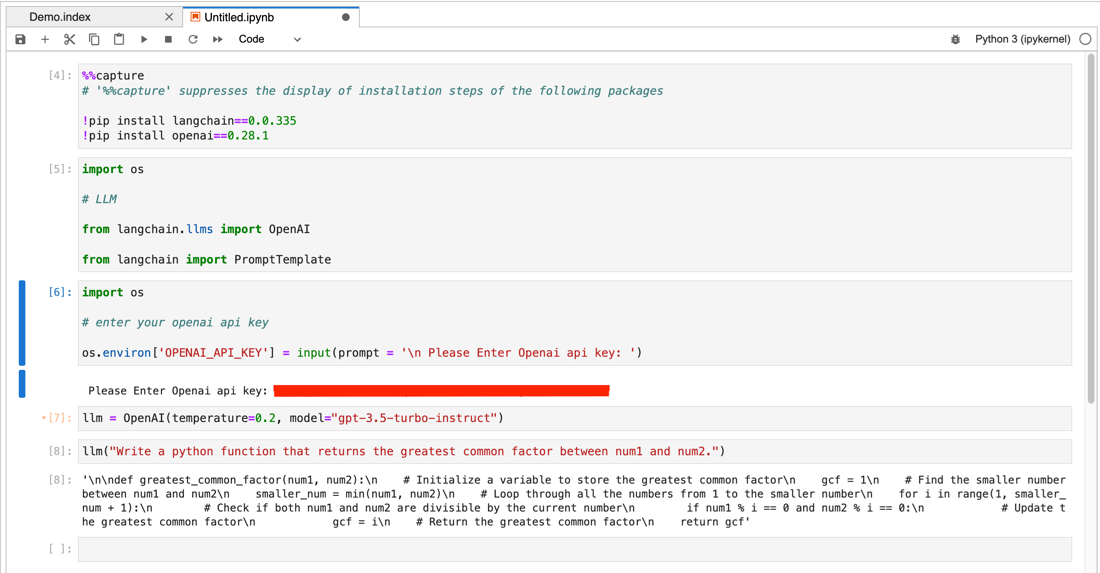
Let’s install and import the libraries and modules we will need. Copy and paste the following code into the Jupyter notebook cells and press Shift+Enter to execute it.
%%capture
# '%%capture' suppresses the display of installation steps of the following packages
!pip install langchain==0.0.335
!pip install openai==0.28.1
import os
# LLM
from langchain.llms import OpenAI
from langchain import PromptTemplate
import os
# enter your openai api key
os.environ['OPENAI_API_KEY'] = input(prompt = '\n Please Enter Openai api key: ')
You’ll need an OpenAI API key. If you don’t have one, please refer to the instructions provided in our guide to obtain your OpenAI API key: Navigate to UseCases/Openai_setup_api_key/Openai_setup_api_key.md.
Once you’ve input your OpenAI API key, you can initiate the LangChain LLM class for OpenAI. The temperature parameter can be set between 0.0 and 1.0. The closer the temperature is to one, the more random its result will be, introducing a higher degree of unpredictability. A number closer to zero will return a focused answer.
llm = OpenAI(temperature=0.2, model="gpt-3.5-turbo-instruct")
We will ask GPT3.5-Turbo-Instruct to solve a coding challenge. To do this, we simply invoke the question like so:
llm("Write a python function that returns the greatest common factor between num1 and num2.")
Jupyter Notebook Setup: Installing Libraries and Importing Modules
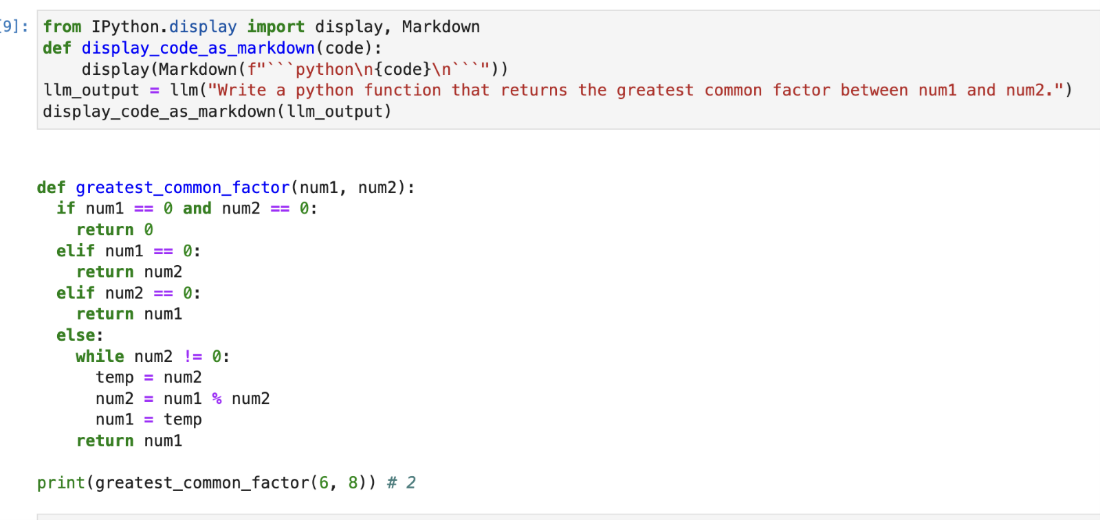
We can return the output in an easier-to-read format in our Jupyter notebook environment by importing the display and markdown modules of IPython.
from IPython.display import display, Markdown
def display_code_as_markdown(code):
display(Markdown(f"```python\n{code}\n```"))
llm_output = llm("Write a python function that returns the greatest common factor between num1 and num2.")
display_code_as_markdown(llm_output)
Output:
Displaying Code Output as Markdown in Jupyter Notebook
Fantastic! Now, let's utilize the PromptTemplates class from LangChain and integrate our five key elements of prompt engineering. This approach will help us guide our model's output effectively. We’ll merge these elements to establish a structured framework aimed at generating targeted and informative responses to programming challenges.
- Instruction. "Act as a computer science instructor." The instruction sets the role for the model, guiding it to respond as if it were a computer science instructor.
- Context. “Given a coding challenge: {challenge} and a coding language: {language}.“ This provides the necessary context for the task, informing the model about the nature of the problem (coding challenge) and the specific programming language to be used.
- Input. In the template, the input will be represented by our parameters, {challenge} and {language}, which will be replaced with specific coding challenges and languages in real scenarios.
- Output Instruction. "Walk the student through identifying the best answer to solve the coding challenge using pseudo-code and finally provide the answer in code." This directs the model on the format and method of response: a step-by-step guide in pseudo-code, followed by the actual code solution.
- Few-shot prompting/in-context learning. We’ll provide an example in the template to illustrate how the model should approach the task. An example acts as a guide for the model, showing it the expected structure and depth of the response.
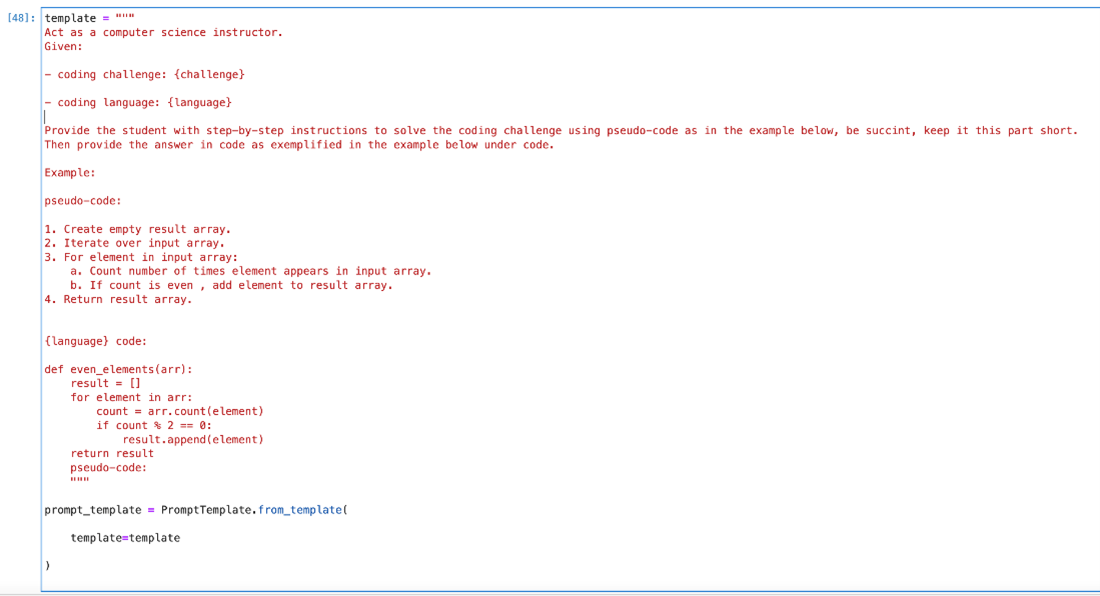
Let’s define our template as follows:
template = """
Act as a computer science instructor.
Given:
- Coding challenge: {challenge}
- Coding language: {language}
Provide the student with step-by-step instructions to solve the coding challenge using pseudo-code as in the example below, be succinct, keep this part short. Then provide the answer in code as exemplified in the example below under code.
Example:
Pseudo-code:
1. Create an empty result array.
2. Iterate over input array.
3. For each element in input array:
a. Count the number of times the element appears in the input array.
b. If the count is even, add the element to the result array.
4. Return the result array.
{language} code:
def even_elements(arr):
result = []
for element in arr:
count = arr.count(element)
if count % 2 == 0:
result.append(element)
return result
Pseudo-code:
"""
prompt_template = PromptTemplate.from_template(template=template)
Defining a Template for Coding Challenges
Note that, in our prompt_template, we end with pseudo-code. We do this because LLMs are prediction engines that pick the most likely next token given our context. By ending our prompt with the start of the output structure, we hint to the LLM that it should complete the next line. We have already instructed that it should be pseudo-code followed by the actual code.
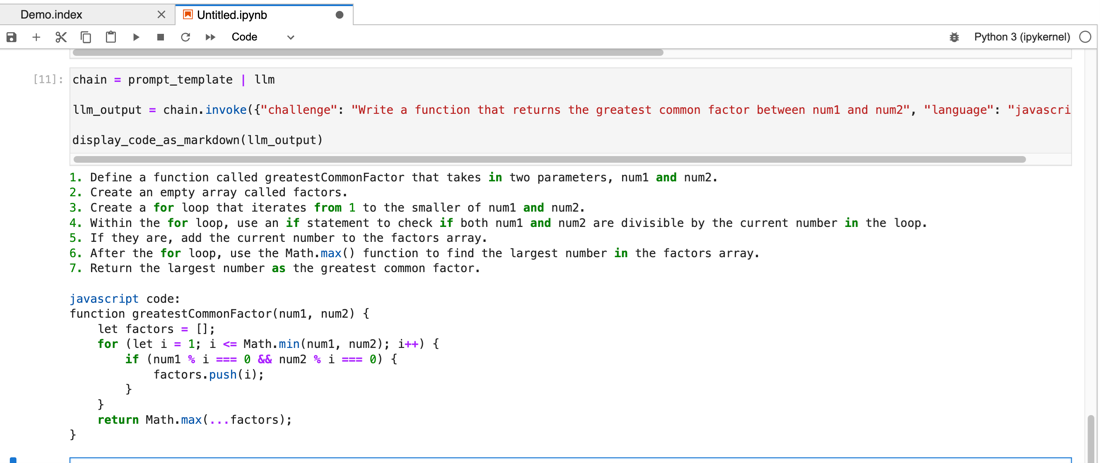
Now we can effortlessly combine our template and LLM using the pipe operator (chain = prompt| model). Additionally, we use chain.invoke() to execute our call to OpenAI and pass in our arguments as a dictionary.
chain = prompt_template | llm
llm_output = chain.invoke({"challenge": "Write a function that returns the greatest common factor between num1 and num2", "language": "javascript"})
display_code_as_markdown(llm_output)
Chaining Template and Language Model (LLM) to Generate Code Output
Congratulations on your progress in learning LangChain's framework for interacting with an LLM! You can take this simple template and easily reuse it for any coding challenge, for any language, with any LLM supported by LangChain.
You've now learned and applied elements of prompt engineering, guiding OpenAI's LLM to produce specific responses. Additionally, we've explored how to craft reusable prompts and effectively leverage LangChain's unique chain functionality. This feature has been instrumental in linking our PromptTemplate seamlessly with our LLM requests.
In the second part of our series, we’ll utilize these skills to query VantageCloud databases using conversational English. This is where the concept of chains in Langchain becomes particularly powerful. LangChain will feed the user’s question, alongside database metadata and our custom prompt, into the first link of the chain involving the LLM. The LLM will identify the appropriate table and craft a query in Teradata SQL dialect. The second link in the chain involves LangChain taking this SQL query and executing it against the appropriate database table. Finally, the query results are sent back through the chain to the LLM, enabling it to generate an English answer based on the data retrieved. Results are presented to the user in an easy-to-understand format, following our tailored output prompt instructions.
Stay tuned!